

Per poter fornire i servizi che gli utenti usano quotidianamente il data center ReCaS-Bari utilizza diversi componenti, ciascuno con una propria criticità.
Ognuno di questi componenti genera una considerevole mole di informazioni, fondamentali per il buon funzionamento del data center, e, di conseguenza, una quantità di dati non trascurabile in termini di spazio disco necessario per la loro memorizzazione. La raccolta di questa notevole quantità di dati sarebbe però del tutto inutile se non fosse affiancata da una modalità semplice ed intuitiva di presentare le informazioni raccolte; per far sì che il messaggio in esse contenuto giunga tempestivamente ed in maniera efficace al gestore della infrastruttura e all’utente.
A questo scopo ci si è indirizzati verso grafana.org come strumento per la visualizzazione dei dati di monitoring del data center ReCaS-Bari. Grafana permette infatti di creare dashboard personalizzate, con o senza autenticazione, con le metriche che più interessano.
L’attività del data center può essere monitorata attraverso il link:https://grafana.recas.ba.infn.it:3000/d/000000016/recas-bari
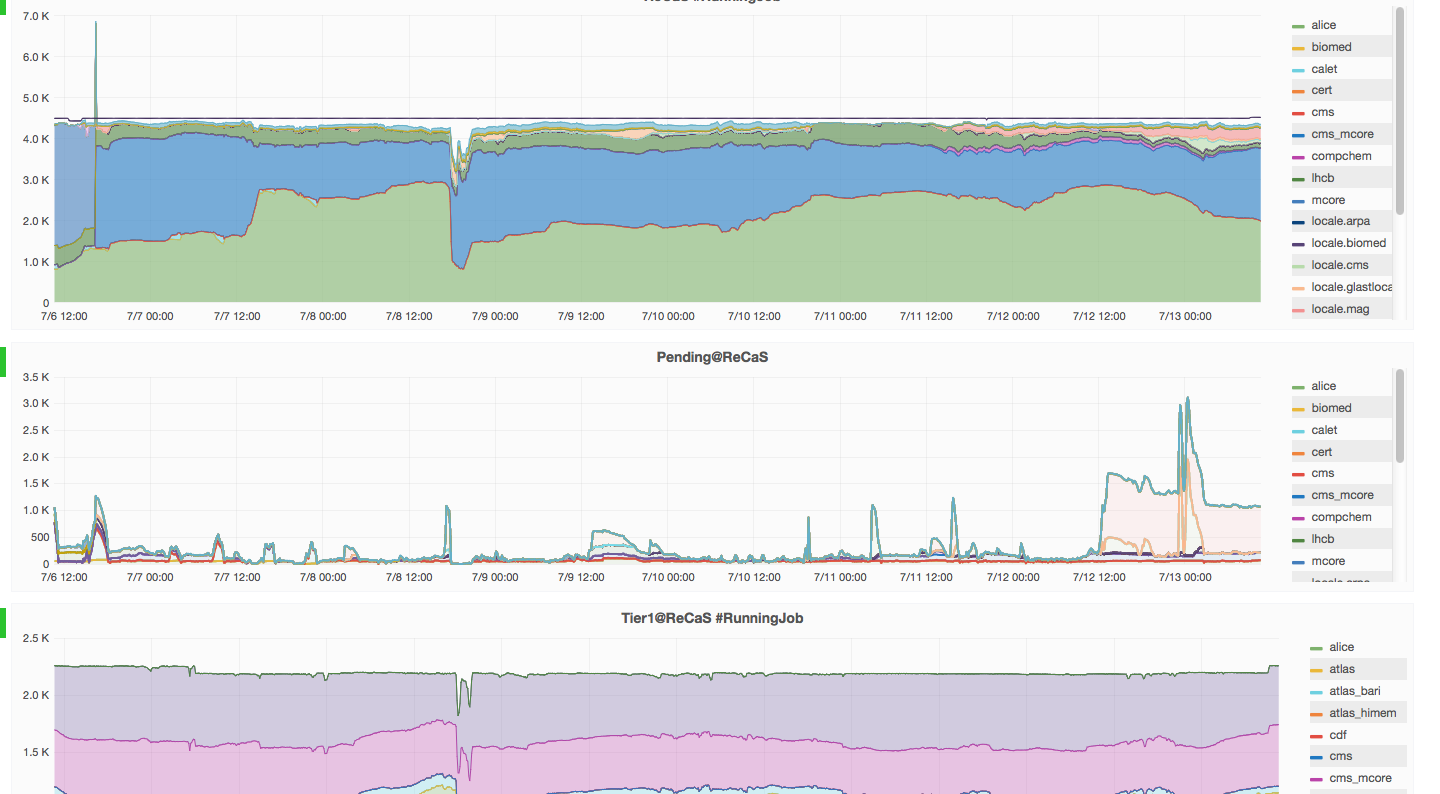
Selezionando questo link si arriva ad una "dashboard" che presenta tre bande:
- La prima banda mostra gli slot (CPU_core) occupati. La linea continua scura più alta nel grafico, denominata "cores", mostra il numero di slot (CPU core) disponibili al sistema batch HTCondor in funzione del tempo (si noti che presenta pochissime variazioni). Le bande colorate danno invece una indicazione degli slot utilizzati da ciascuna delle Virtual Organization, VO, che eseguono Job sul sistema di batch HTCondor. Selezionando una particolare VO dall'elenco a destra si possono visualizzare solo i dati corrispondenti a quella particolare VO. Di default vengono mostrati i dati relativi all'ultima settimana ("Last 7 days"). Cliccando su "Last 7 days", in alto a destra, si può selezionare un intervallo diverso.
- La seconda banda mostra invece, sempre per ciascuna VO ed in funzione del tempo, il numero di job in attesa di essere eseguiti sul sistema di code batch HTCondor.
- Infine, poiché alcune delle risorse del data center ReCaS-Bari sono utilizzate direttamente in remoto dal Tier1 dell'INFN situato a Bologna e gestito dal CNAF, nell'ultima banda si può vedere l’uso delle slot che sono a disposizione del TIER1 in funzione del tempo e per ciascuna VO,
Invece seguendo il link: https://grafana.recas.ba.infn.it:3000/d/000000020/accounting-htcondor-recas-donut
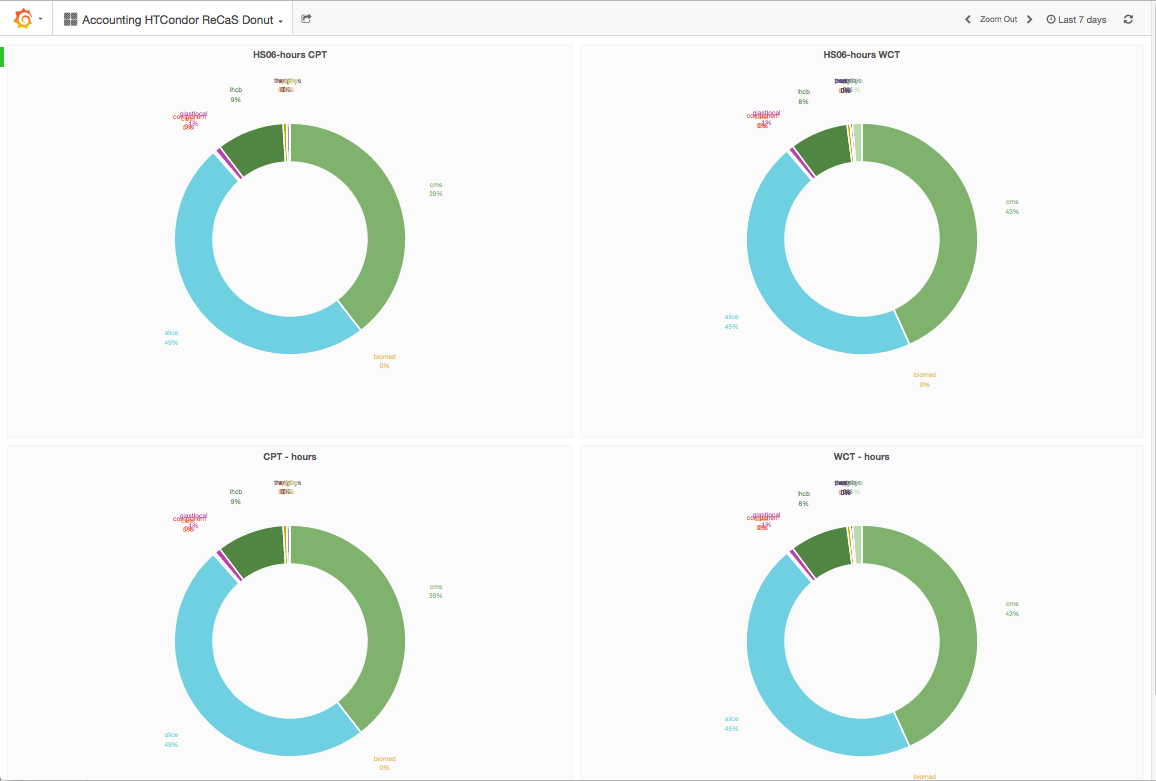
si seleziona una pagina che presenta la ripartizione tra le varie VO (attraverso diagrammi a torta) dell'uso, nell’ultima settimana, delle risorse disponibili al sistema di batch HTCondor nel data center ReCaS-Bari. Naturalmente l’intervallo di tempo può essere selezionato dall’utente cliccando su “ Last 7 days” in alto a destra.
Vengono mostrati due grafici separati sia per il Wall Time (il tempo di occupazione della risorsa) che la CPU Time (l'uso effettivo delle risorse epurato dai tempi di attesa per della lettura dei dati dallo storage). L'uso delle risorse viene mostrato sia in unità di "ore_core", che in HS06_hour (tipicamente una CPU core di ReCaS-Bari ha una potenza computazionale di circa 10 HS06).
Seguendo infine il link:
https://grafana.recas.ba.infn.it:3000/d/000000019/accounting-htcondor-recas?orgId=2 si arriva ad una pagina che presenta quattro bande.
La prima banda è uno “stacked histogram”, che mostra, giorno per giorno, il numero di HSE06*giorno complessivamente utilizzato, mettendo in evidenza il contributo di ciascuna VO al consumo complessivo. L’HSE06 è una misura della potenza computazionale. L’uso di un core di ReCaS-Bari per un intero giorno corrisponde ad un consumo di circa 10 HS06*giorni.
La seconda banda mostra, giorno per giorno, il numero di job complessivamente sottomessi e la modalità con cui sono stati sottomessi
-
via grid: CE-01, CE-02, CE-03
-
mediante sottomissione locale: Ettore
Per default il numero di job mostrati è quello totale relativo a tutte le VO (VO=All). E’ però possibile scegliere nel menù a scelta multipla, denominato “VO”, in alto a sinistra nella pagina, una o più VO. In tal caso il numero di job mostrati in questo istogramma sarà la somma del numero di job sottomessi dalle VO selezionate.
La selezione della VO si applica non solo questo istogramma ma anche a quelli della banda tre e quattro.
La terza banda riporta il consumo complessivo giornaliero delle risorse di calcolo. Quando tutte le VO sono selezionate (VO=All) questo istogramma è del tutto equivalente a quello mostrato nella prima banda a parte il frazionamento per VO. Se però attraverso il menù VO, in alto a sinistra, si seleziona una particolare VO, l’istogramma mostra il consumo giornaliero di risorse di calcolo attribuibile a quella particolare VO.
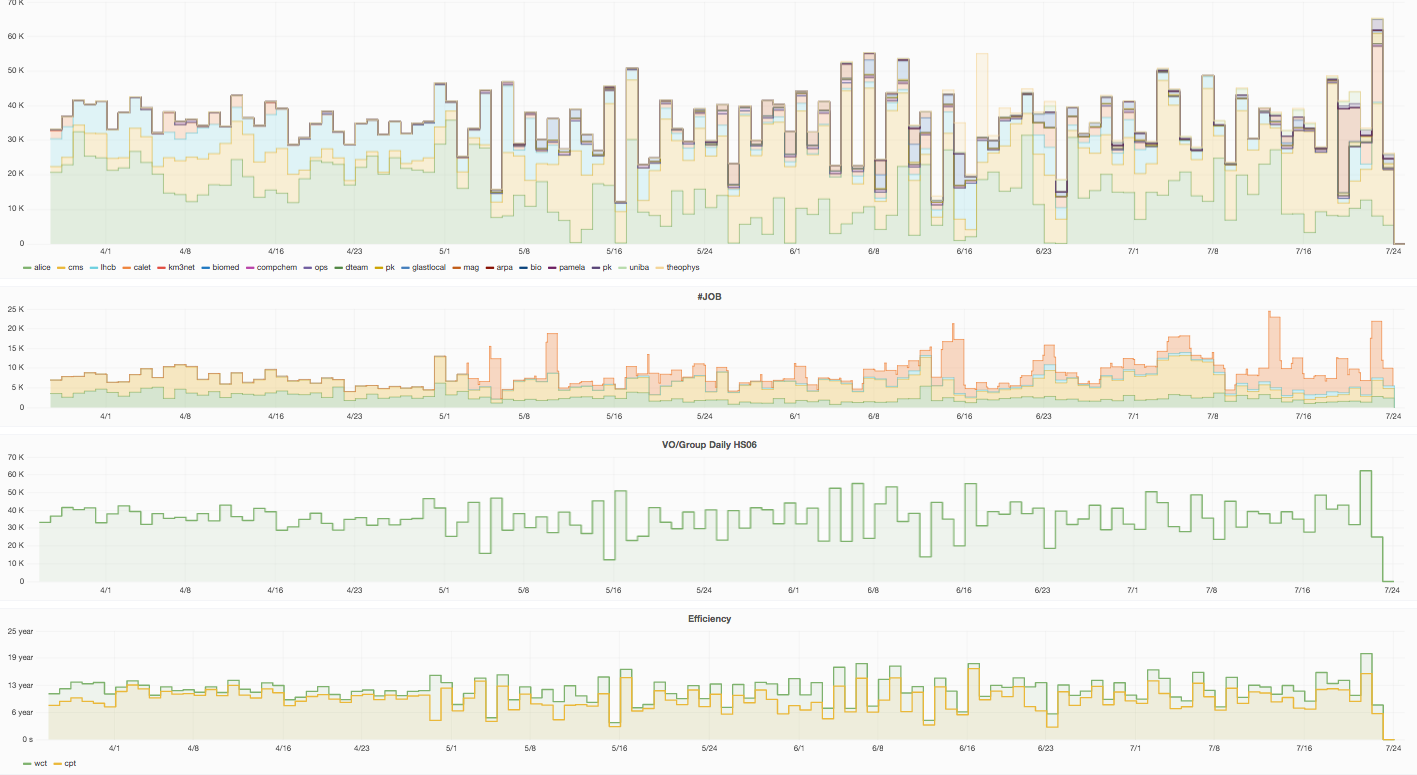
Particolarmente significativi sono i due istogramma riportati nell’ultima banda. Essi si riferiscono infatti al CPU Time, il tempo di effettivo uso delle CPU sovrapposto al Wall Time, il tempo effettivo di occupazione della macchina. Questo tempo è sempre più grande del CPU Time perché al tempo di effettivo uso delle CPU bisogna aggiungere il tempo di attesa per la lettura dei dati dallo storage. In effetti, si vede dagli istogramma che il Wall Time sovrasta in tutti i bin il CPU Time.
Tanto più piccola è la differenza tra questi due istogrammi, tanto più veloce è la lettura dei dati dallo storage. Questi due istogrammi danno quindi una indicazione visiva della efficienza dell’uso dell’infrastruttura di calcolo da parte delle diverse applicazioni che girano sulla farm. Per default sono mostrati il Wall Time e il CPU Time di tutte le VO, ma come già detto, selezionando attraverso il menù a scelta multipla, la/le VO di interesse si può restringere il confronto alle VO selezionate.